I’ve been working on a couple of very interesting projects recently, where’ve tried to use the powers of ChatGPT in languages different than English. In all three projects, we were looking for pretty similar things.
Objective: For ChatGPT to be able to write as human-like as possible, creative, and personalized texts.
Results were somewhere more, somewhere less successful, but we learned a lot! When I say we I’m talking about our awesome team at Escapebox and amazing people from Luna/TBWA and Argeta, Atlantic Grupa.
In this blog post, I’ll highlight how we approached the process, what we did, and what we figured out along the way.
While AI models are becoming increasingly adept at mimicking human language, opening new avenues for applications like creating captivating, personalized stories or character descriptions, we wanted to put this to the test.
In the last six months, we created:
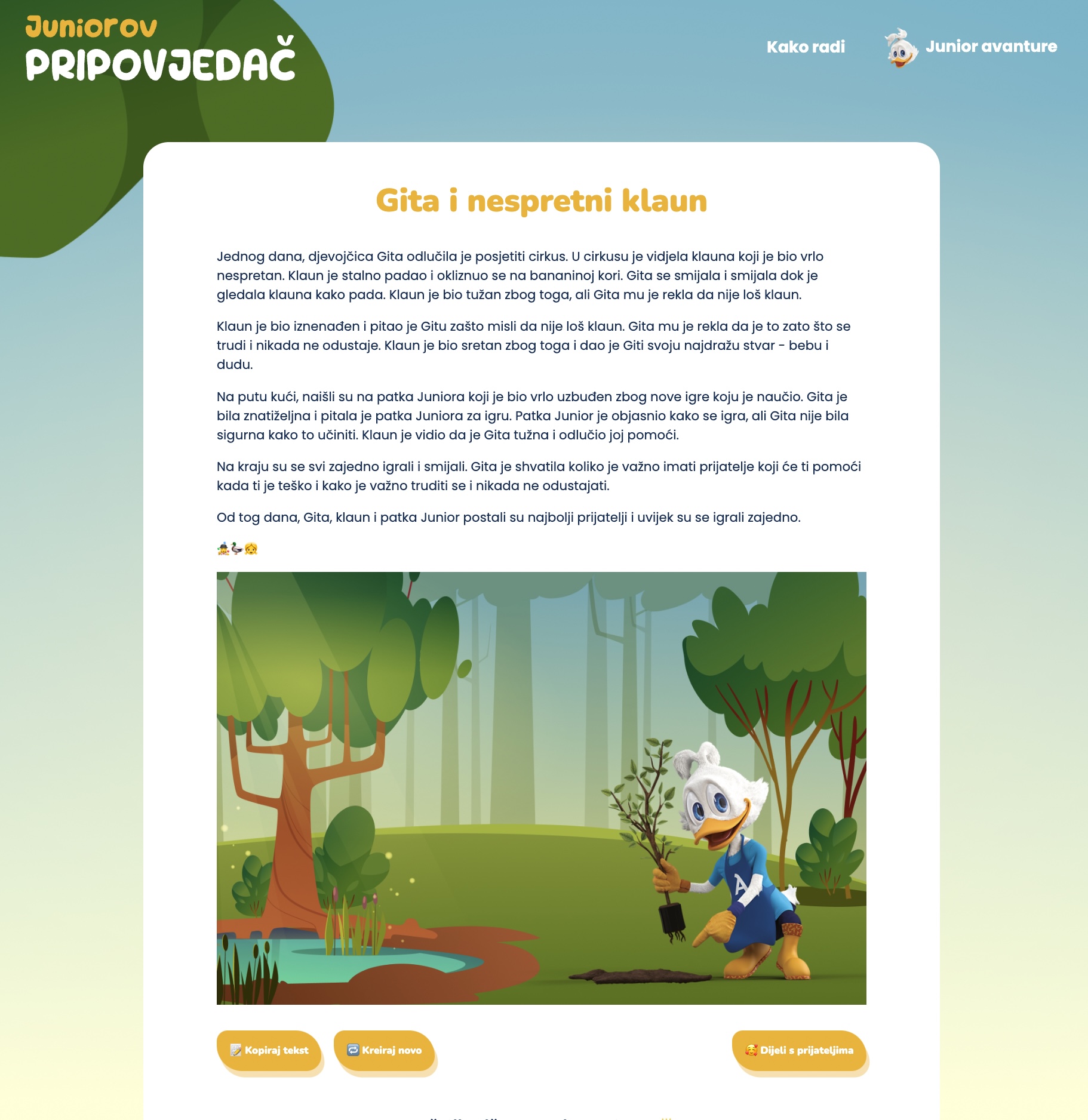
- A birthday ghostwriter (works in two languages, been used in 20+ countries) see
- A creative storyteller (works in three languages, used in three countries) see
- A movie quizbot (runs in two languages – Bosnian and English) see
I was responsible for leading prompt engineering and app interface development of all three.
Besides the projects, I was spending my nights learning about and building with prompts. For our company’s needs, I created a couple of really powerful ChatGPT personas for digital marketing managers that help us so much with writing, iterating, coding, outlining, concepts, advertising, and so forth.
I’ve learned that the essence of harnessing the full potential of ChatGPT in non-English language outputs lies in the precision and quality of its responses. Whether you’re using it for customer support, content creation, or personalized interactions, maintaining high-quality output in the desired language is critical.
How ChatGPT Learns from Data and how to leverage that to your advantage?
I’ll be brief here, since you can learn more about this directly on ChatGPT with just casual curiosity on how it’s built, how it can or cannot behave, how can it be trained and so on.
And also because I wrote about this in my other blogpost about ChatGPT personas.
But in general, the best results will always be achieved with feeding the model with a robust collection of text in the desired language. The data that ChatGPT learns from plays a vital role in understanding and responding in non-English languages.
But what it you don’t have that option (you can’t) or if you want to just work with the general ChatGPT model and its existing data?
Well then, you learn how to shape a prompt to suit your needs and test the living shit out of the model with different settings.
Keep in mind,
ChatGPT is a transformer-based model, with layers upon layers of neurons, all interconnected, and communicating in a language of zeros and ones.
It consumes up every piece of text you feed it and stores it somewhere in its artificial noggin. It’s a bit like having a constantly hungry teenager who devours everything in the fridge, only this one has an insatiable appetite for words, phrases, and context.
When you command ChatGPT to spit out a response in a non-English language, it dives headfirst into its massive collection of data. It sifts through countless instances of past input in the target language, stringing together coherent and contextually appropriate responses.
But here’s the kicker, the model itself does not truly “understand” the language, per se.
Instead, it’s more like a master parrot, incredibly good at mimicking language patterns it’s seen before.
That’s why feeding ChatGPT with a variety of high-quality, context-rich texts in the target language is like giving it a masterclass in that language. However, let’s say you’re in a bit of a pickle and don’t have the luxury of a curated dataset in your target language or the resources to create one.
Well, that’s where things get really fun.
You learn to be the puppet master, deftly shaping and molding your prompts to get exactly what you want. It’s like teaching your pet to perform tricks, only in this case, the pet is an AI and the tricks are your text outputs. And yes, you’ll have to get your hands dirty by testing the bejeezus out of the model with various settings, tweaks, and iterations. But hey, that’s where the magic happens, right? Stick around, we’ll delve into all of that and more.
How to train ChatGPT for best Non-English results?
This approach is fundamentally built on two critical layers that work in synergy to deliver the desired outcome.
The first of these is the front-end user interface – this is the space where users interact with the application, selecting their preferences and feeding their inputs into the system.
The second component is the backend translator. Acting like a behind-the-scenes hero, this layer takes the front-end selections and transforms them into more detailed prompts that are then sent to the API. By working in tandem, these layers allow us to provide a seamless user experience while effectively leveraging the capabilities of ChatGPT.
Front-end interface (with real-life example)
When building a ChatGPT application, it’s crucial to take a holistic approach from the get-go. This means that while designing the front-end interface, the backend logic must be considered simultaneously. Only then can we ensure the user’s input selections translate seamlessly into effective backend prompts. Let’s take a deeper look at this concept using two different real-life examples: BirthdaiCards and Movie Alterego quiz.
BirthdaiCards: Tailored Outputs through User Selectors
The BirthdaiCards application showcases how user selectors can shape the ChatGPT output.
Here, the user interface asks for specific information about the recipient, such as their gender, age, name, type of birthday card, interests and so on.
These inputs not only help in personalizing the card but also determine the language style, tone, and content that ChatGPT will generate. By carefully tailoring these front-end selectors, we are able to guide the backend to produce highly personalized and appropriate messages that resonate with the intended recipient.

Movie Alterego Quiz: Gathering User Selections through Interactive Content
On the other hand, the Movie Alterego Quiz offers an example of how we can creatively gather user inputs. Instead of asking for direct input, this application poses a series of fun movie-related questions.
The user’s responses to these quiz questions then serve as input selections for the ChatGPT. This makes the interaction more engaging and dynamic, while still allowing us to collect the necessary information to shape the AI responses.

Both these examples demonstrate the importance of designing the front-end interface with a clear understanding of how the backend logic works. By doing so, we can create more effective and engaging applications with ChatGPT.
Creating Backend Translations for Non-English Text Results
Now that we’ve established how the user interface plays an integral role in shaping ChatGPT responses, let’s dig into the backend process of translating these inputs into tailored, non-English outputs.
Even though our front end is feeding ChatGPT with straightforward user choices, what actually arrives at the AI model’s doorstep can be a mixture of detailed and technical descriptors, tailored to guide the model into producing the desired non-English results.
This nuance might seem insignificant at first glance, but it’s here where the magic of our language transformation truly comes to life.
The beauty of these backend translations is their flexibility. They allow us to shape, restructure, and fine-tune the instructions fed to the AI model, without overwhelming the user with complexity.
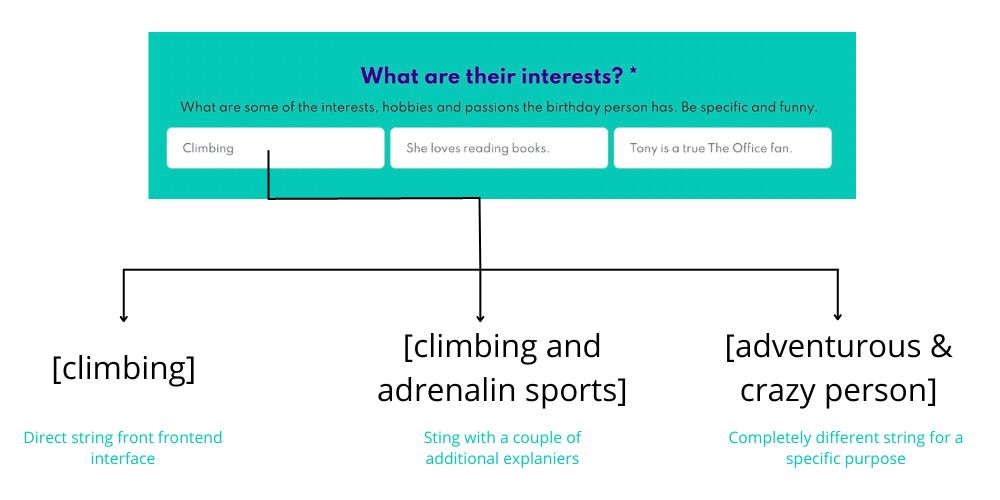
As users interact with our frontend interface, they might simply input their interest as “climbing”. This straightforward input serves as the baseline for our backend translations. It’s simple, and direct, and gives ChatGPT a clear topic to focus on.
However, the power of our backend translations lies in their ability to take this simple user input and expand it in meaningful ways. For instance, we can broaden “climbing” to encompass a larger theme, translating it to “climbing & adrenaline sports”.
This broader theme allows ChatGPT to tap into a wider range of potential conversations, injecting variety and versatility into the generated text.
And it doesn’t stop there.
We can take a step further and translate “climbing” into a character trait like “adventurous & crazy person”. This switch doesn’t explicitly mention climbing but it encapsulates the spirit of a climber, allowing for a much broader range of narrative possibilities.
Instead of being limited to explicit references to climbing, ChatGPT can now explore topics and narratives associated with being adventurous and thrill-seeking.
This example illustrates the power of backend translations and how they allow us to manipulate the user’s inputs in order to get the most out of ChatGPT. It’s like a dance between keeping the essence of the user’s input and expanding on it in creative and unexpected ways.
And the best part is, we can keep testing, refining, and optimizing these translations to create the most engaging and personalized non-English outputs possible.
Through this process, we can continually refine and optimize these translations to test different results and achieve the highest quality of non-English language outputs. It’s a process of continual learning, adjustment, and testing, but the end result is a well-honed system that can generate rich, personalized, and creative texts in various languages – all from a few simple user inputs.
And now finally …
How to set up rules for ChatGPT non-English results
An essential step in our process was developing a specific language Competence Map. The purpose of this map was to articulate the knowledge boundaries for a specific language, in this case, Slovenian.
For instance, we defined that the model understands Slovenian culture, geographical landmarks, and popular local events, and is aware of the latest Slovenian books and movies up until 2021. It could also discern between formal and informal Slovenian language, as well as understand the subtleties of Slovenian slang.

Now, as the competence map provides a general framework, we drilled down into more specific rules to guide ChatGPT in generating localized content. These rules played a vital role in ensuring that the language output met our standards of quality and relevance.
Here are two general examples:
Always write in grammatically correct Slovenian
We implemented this rule to maintain high standards of linguistic integrity. Regardless of how complex the translation might be, we prioritized linguistic correctness above all. This rule is key for any non-English language you might be working with, as grammar rules significantly differ across languages.
Write in the [first/second/third] person
This rule was employed to make the content feel more personal and engaging to the user. For instance, rather than saying “The individual is truly a thrill-seeker“, the bot would use the more direct approach. “You truly are a thrill-seeker“. This change in perspective instantly makes the conversation feel more personal and direct.

These steps – hough might appear simple – played a significant role in tailoring the performance of ChatGPT to generate high-quality, non-English language outputs.
And the beauty is that these methods can be applied to virtually any language! With adjustments made based on the unique features and quirks of the language in question.
With this process, we were able to harness the full potential of ChatGPT. Crafting engaging, personalized, and linguistically sound content that truly resonated with our non-English speaking audience.
Remember, the key is always in the details.
With careful planning, exhaustive testing, and continuous iteration, you too can tap into the impressive capabilities of ChatGPT to create meaningful, captivating content in any language.
It’s always better to start with too many rules and then systematically strip the model down by comparing the results.
💡 PROTIP: Use ChatGPT to help you create rules & descriptions for the specific role you are crafting for it.
Final thoughts
The iterative nature of the process cannot be overstated.
You could say it’s the heart and soul of making the most out of ChatGPT. For instance, in the making of Junior Zgodbarček, over 1500 tests were carried out to finely tune the output. Similarly, the Movie Alter Ego bot took more than 400 iterations. And Birthdai Cards required over 350 tests to hit the mark.
And I’m not even kidding. But the thing is, once you have front-end interface done, testing and iterating become a lightning speed process.
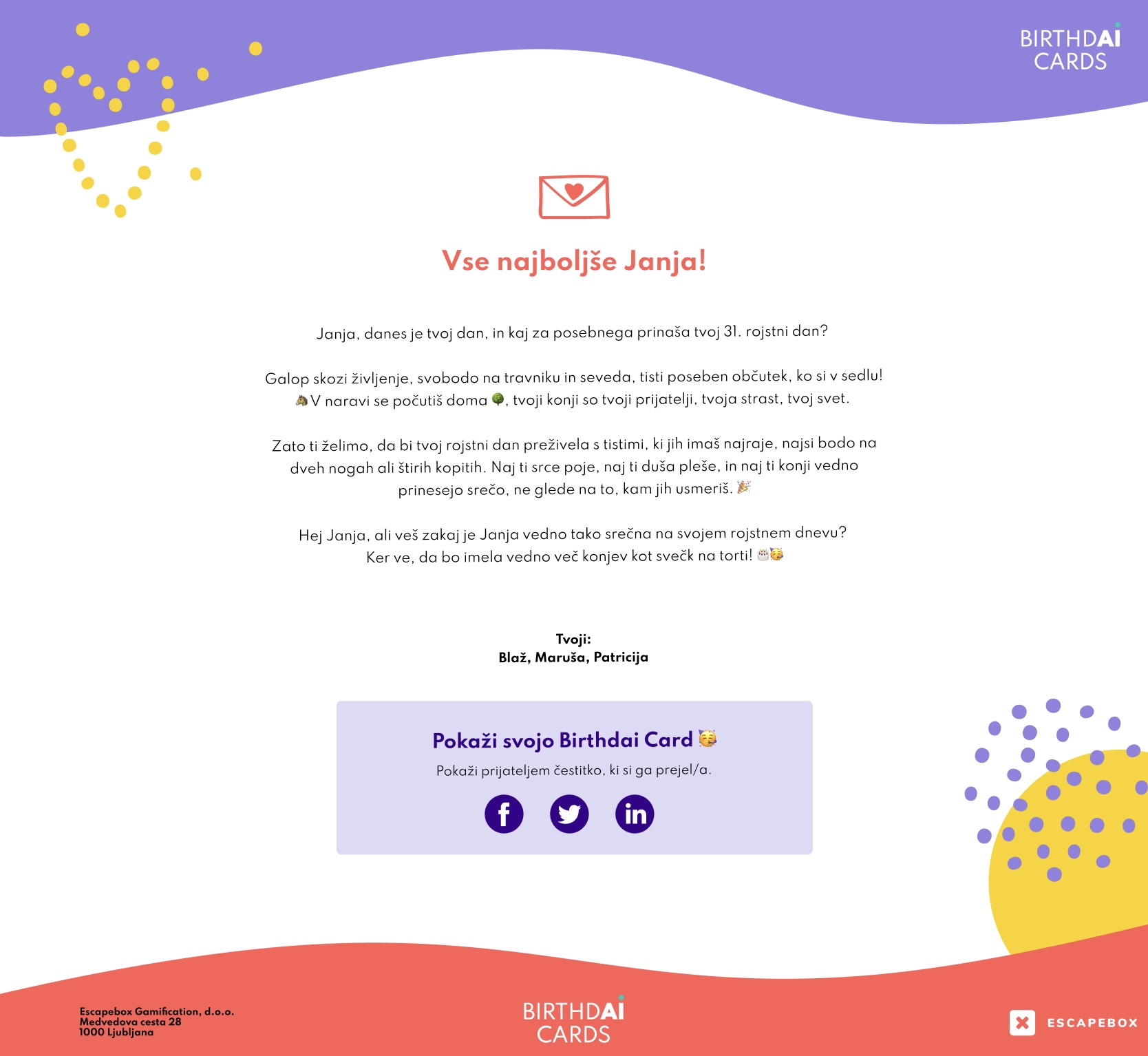

Remember!
Creating effective and engaging AI content isn’t a one-shot affair. It’s a process of continual refinement and adaptation. It’s about finding what works and what doesn’t, and then adjusting your course accordingly, and being patient, meticulous, and persistent.
But it’s also important not to get lost in the weeds. With all the iterations and adjustments, it can be easy to lose track of what changes were effective and which ones weren’t.
Keeping a clear log of modifications, testing rigorously, and learning from each result is vital.
So, as you embark on your journey to create compelling content in non-English languages, remember this: iterate, record, learn, and repeat.
And of course, don’t forget to enjoy the process. Here’s to creating engaging, personalized, and captivating AI content in any language you choose.
And one more little secret If you came all the way to the end …
ChatGPT will return even better localised results if you interact and work with it directly in the language your output requires. So, If you want the best results in Slovenian language, you should work mostly with slovenian language (system prompt, user prompts, rules and fron-end interface).
If you liked this breakdown, you can check my ChatGPT for digital marketing Playbook, and get six incredibly powerful ChatGPT personas to work faster and smarter.