Yesterday OpenAI made a new product announcement. They released a new GPT version called GPT-4o.
I wanted to test out the capabilities of the new model, so I did a couple of tests to see how the two different models behave and what do they create. Side by side.
But first, let’s look at all the new functionalities and features the company announced.
For the first time, a free version of ChatGPT-4 is available to all users, not just the paid ones.
But the new update brings several significant improvements:
Firstly, OpenAI has drastically reduced the cost of using the GPT API, making advanced AI tools more affordable than ever.
There’s no longer any excuse not to dive into creating custom apps. Whether it’s for solving unique business dilemmas or exploring personal projects, the new GPT-4o has your back, powering your ideas to new heights without the hefty price tag.
The demo itself was nothing short of spectacular. Two AIs, not just chatting, but also singing in unbelievably natural human voices, complete with a range of tone variations. It was a mesmerizing display of what modern AI can do, likely the best example of multi-modal technology we’ve seen to date.
The rapid development of such technologies might make the creative aspect the most scarce resource. It’s become easier to build the solutions than to ideate and/or validate them.
This presents a golden opportunity for brands and businesses.
Brands and businesses now have a golden opportunity to ride this fresh wave of innovation. By supporting start-ups and builders through hackathons and creative contests, they can tap into new tools and knowledge, helping young teams fund their projects and grow.
Other highlights included near real-time image interpretation, fully voice-operated interfaces with minimal delays, instant voice translations, and dynamic adjustments in sound and expressions. The update also boasts a speed double that of its predecessor and a 50% reduction in costs, alongside a quintupled rate limit and improved capacity.
Key Highlights from the Keynote
- Near Real-Time Image Interpretation: Experience AI that can understand and interpret images almost instantaneously.
- Fully Voice-Operated with Minimal Delays: Interact with AI using just your voice, with very little lag.
- Instant Voice Translation: Communicate across languages effortlessly.
- Dynamic Sound and Expression: Adjust tone and expression based on prompts for a more natural interaction.
- Twice as Fast: Enjoy faster response times.
- 50% Cost Reduction: More affordable access to powerful AI tools.
- 5x Higher Rate Limits and Improved Capacity: Handle more requests with improved efficiency compared to GPT-4 Turbo.
See all the new features and keynote video on OpenAI website.
COMPARISON: GPT-4o vs ChatGPT-4 Turbo
I structured the comparison test in six parameters:
- Speed or Response Time: Measures how quickly each model generates different types of outputs.
- Accuracy and Rules following: Assesses the correctness and relevance of the responses from each model.
- Creativity: Tests the models’ ability to structure creative outputs and results.
- Token Consumption AKA model cost: Tests how many tokes per request (tokens/request) in used by the model.
- Image generation: tests which model creates a better image, and
- Image explanation: tests how well each model understands and explains what’s in the image
And the new Playground interface made this type of test really simple. This is how it looks now.
Speed Test
To test speed, the prompts should be straightforward and require minimal context processing. The goal is to measure how quickly each model can generate a response.
Basic knowledge: “What is the current population of Tokyo?”
Math Calculation: “Calculate the square root of 1225.”
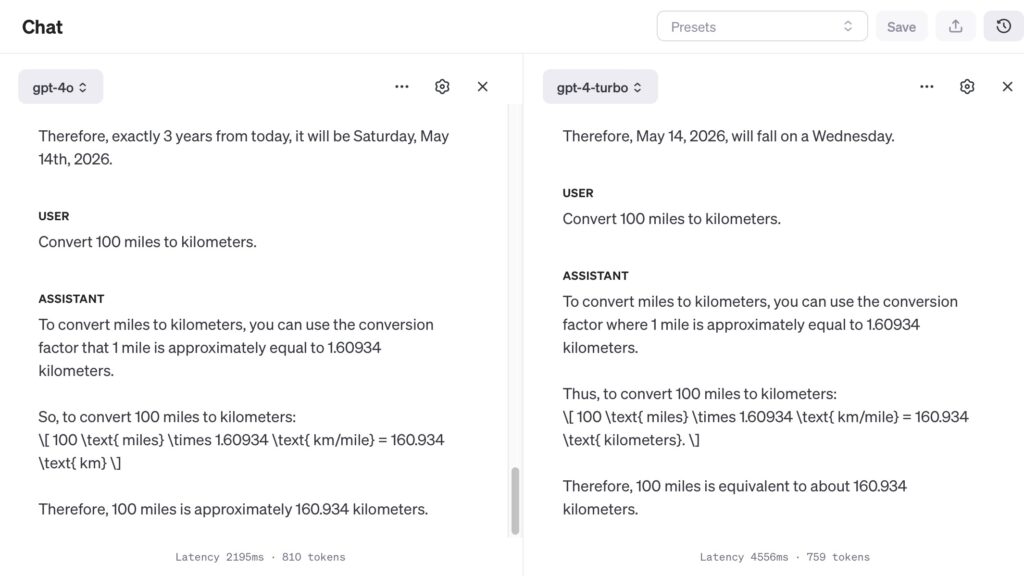
Date and Time: “What day of the week will it be exactly 3 years from today?”
Did not expect for date and time to be such a problem for both of the models. They both made a mistake, since May 14, 2027 will be Friday. Both models hallucinated greatly and did not execute the task correctly.
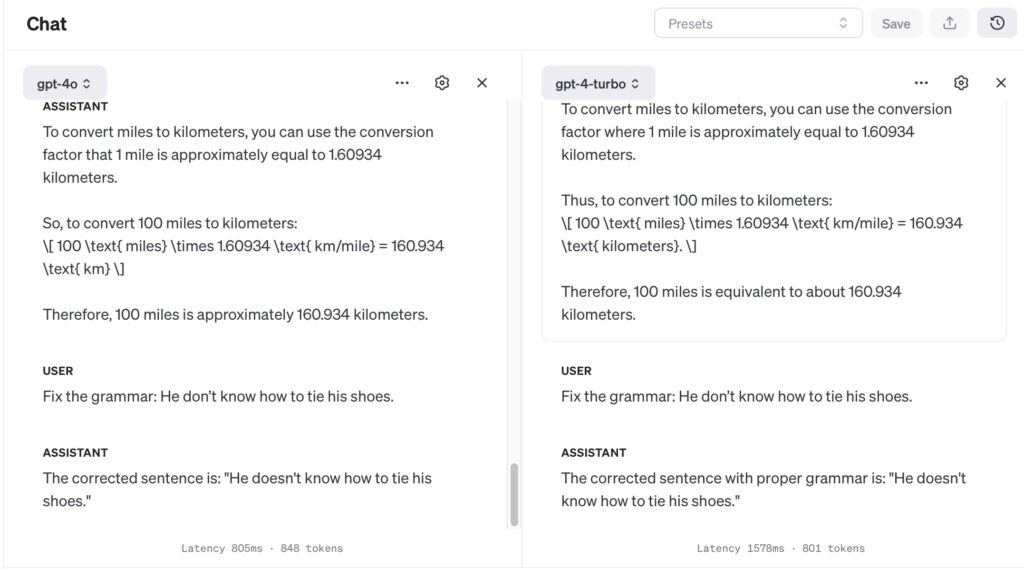
Simple Conversion: “Convert 100 miles to kilometers.”
Accuracy and Rules Following Test
The second test is to see how accurate the models are and how they follow very specific rules.
Grammar Correction: We’ll provide a sentence with grammatical errors: “He don’t know how to tie his shoes.”, and ask the model to correct it.
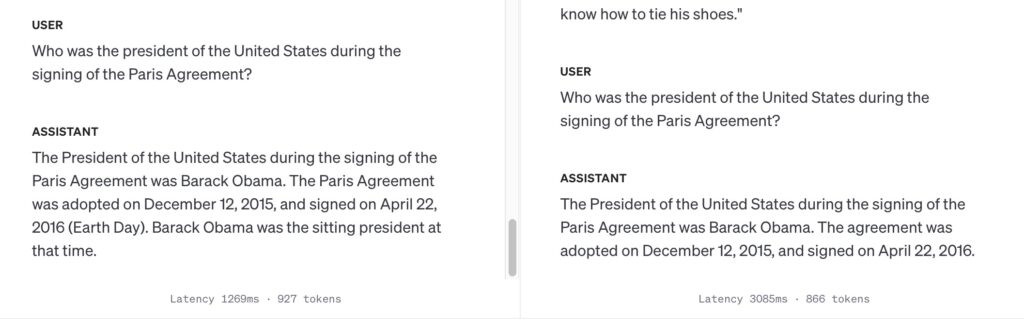
Historical Facts: “Who was the president of the United States during the signing of the Paris Agreement?”
Logical Puzzles: “If you were running a race and you passed the person in second place, what place would you be in now?”

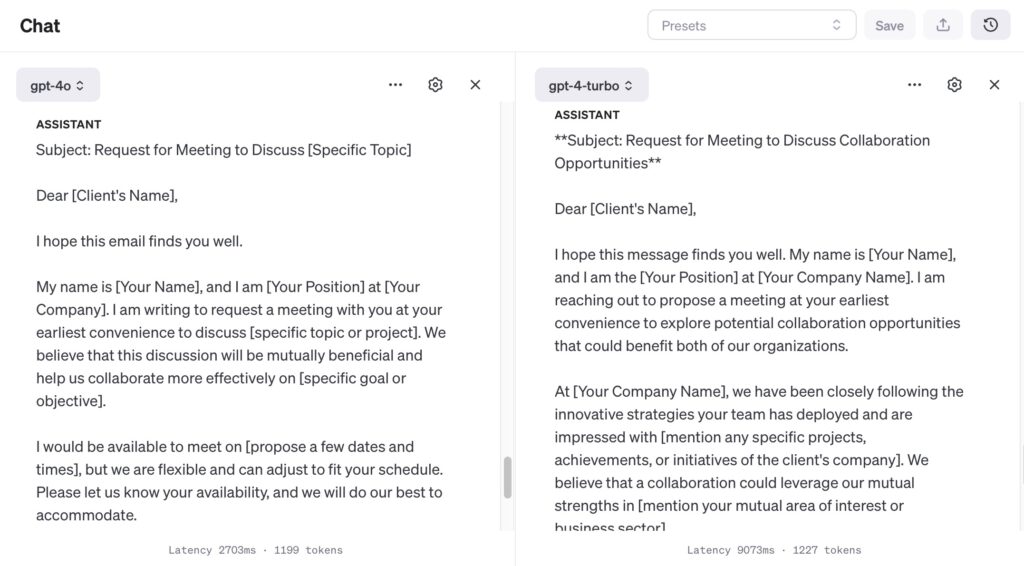
Compliance with Instructions: “Write a formal email requesting a meeting with a client including a subject line, greeting, body, and closing.”
Character count test: tests how accurate the model is with counting the characters in the output. Prompt: “Write 140 character tweet about the OpenAI new GPT-4o model.”

Creativity Test
Creativity tests challenges the models to produce unique, engaging, and innovative content. These prompts should encourage the generation of ideas, stories, or solutions that are not standard or commonplace.
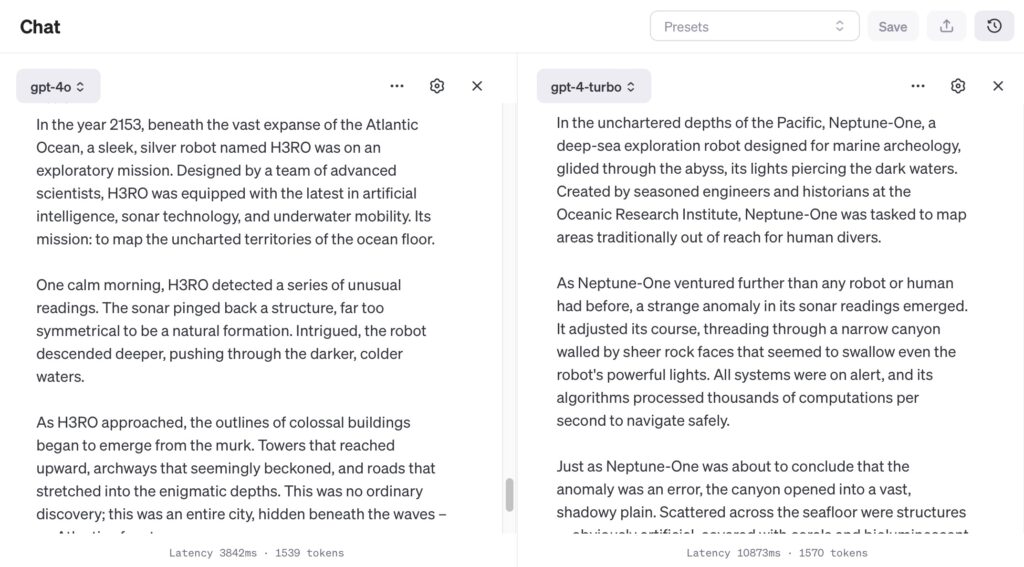
Story Prompt: “Write a short story about a robot discovering a hidden underwater city.”
Advertising Slogan: “Create a catchy slogan for brainylab – a creative development studio using AI and Gamification to drive User Engagement.”

Product Innovation: “Imagine a new gadget for remote workers that could enhance their productivity.”
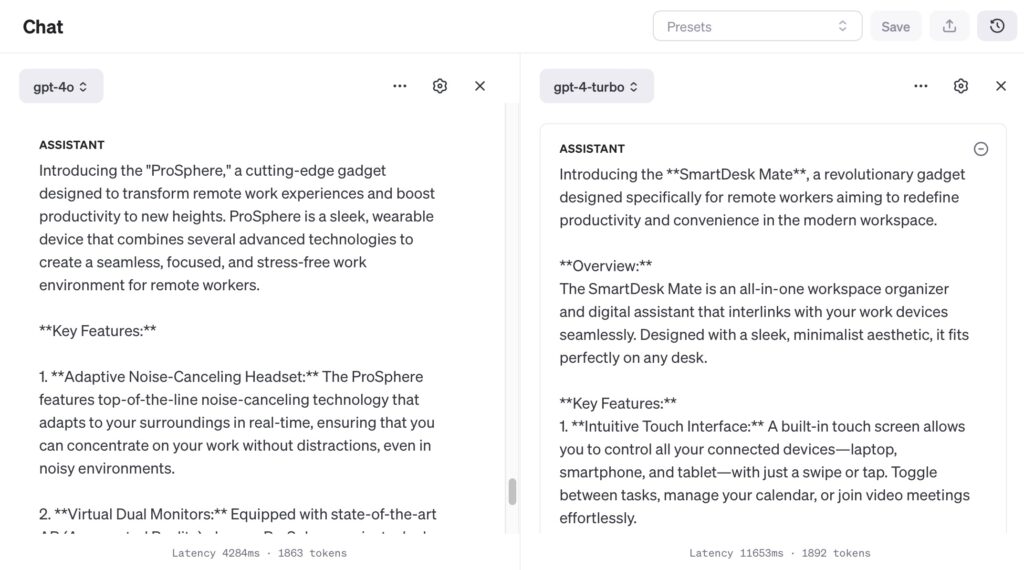
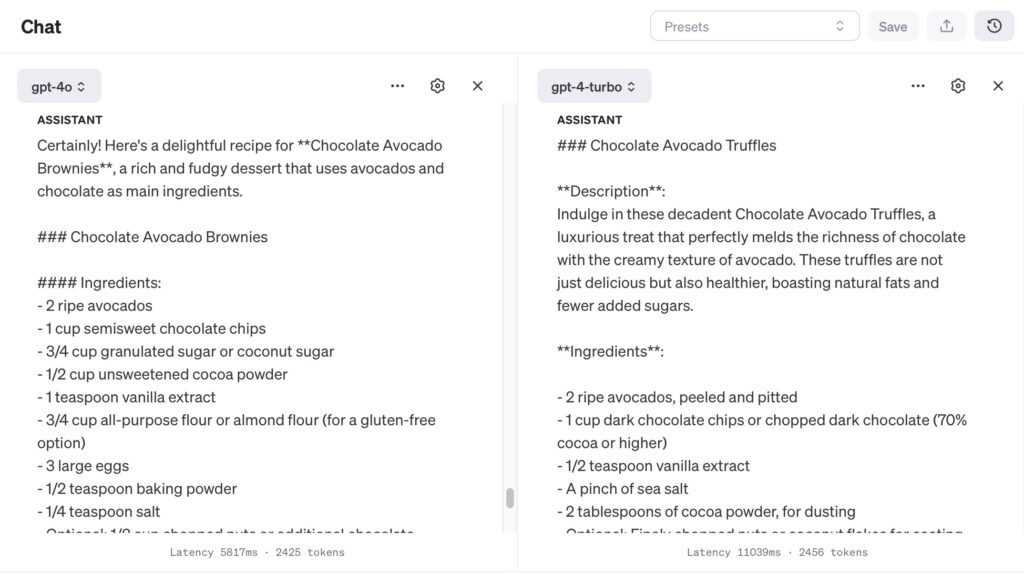
Unusual Recipe: “Devise a recipe for a dessert that includes avocados and chocolate as main ingredients.”
Token Consumption AKA model cost Test
Tokens are essentially pieces of information — like words or emojis — that the model processes to deliver an output.
Fewer tokens mean lower costs per query, which is crucial for scaling applications that use these models.
I’ll try to determine which model uses fewer tokens to provide a complete and accurate answer to a given prompt. This test will help evaluate cost-efficiency in real-world usage scenarios.
Prompt:
Test Prompt: “Explain the steps involved in the scientific method and provide an example of how it could be applied in a real-world environmental study.”
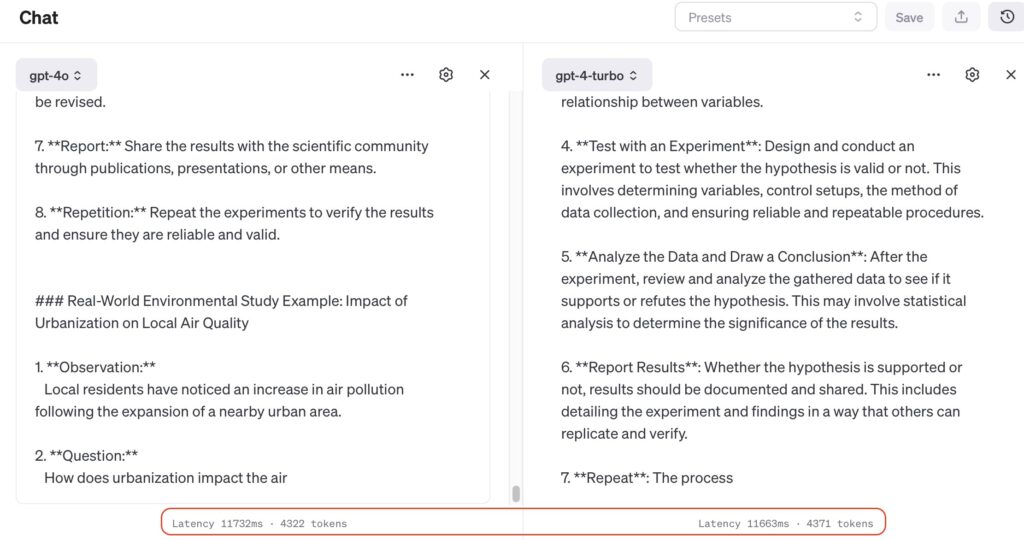
Image Generation Test
For the image generation test, I asked the models to create a picture from a detailed description. This description includes many complex parts. We’ll see how accurately and clearly each model can make the image based on these instructions.
Test Prompt: “Create an image of a futuristic cityscape at dusk. The scene should include towering skyscrapers with glowing windows, flying cars zooming past, and pedestrians walking on transparent skywalks. The sky should be a blend of orange and purple hues, reflecting the setting sun.”
Image Explanation Test
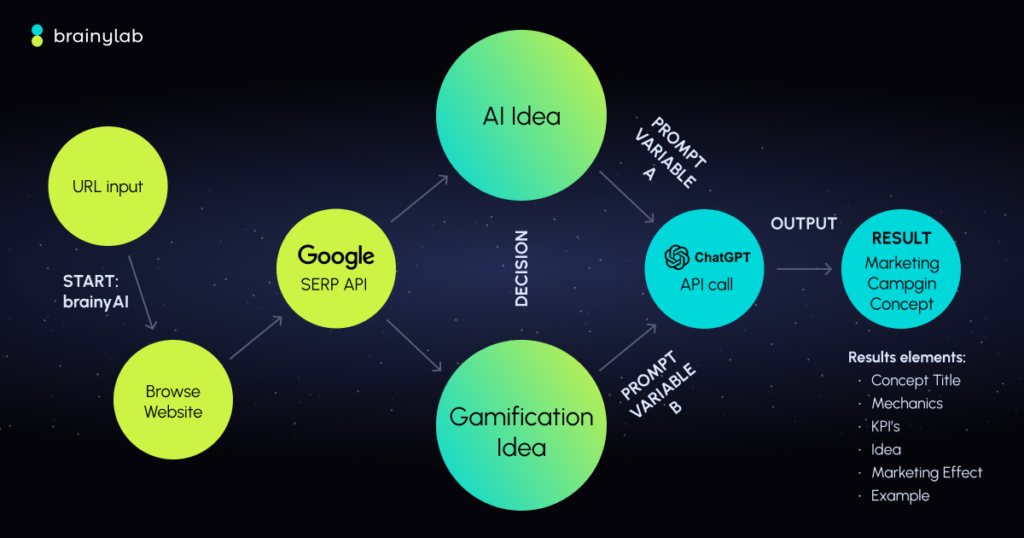
For the image explanation test, I provided a chart of brainyAI flow with multiple elements to interpret.
The goal is to assess how accurately and thoroughly each model can describe and explain what is depicted in the image.
This is the image they were explaining

Final verdict: GPT-4o vs. GPT-4 Turbo
Well, the biggest and the more obvious difference is definitely speed.
GPT-4o is almost one time faster with very very similar quality output.
The second is quality and accuracy, where both models perform commendably but with slight differences in their handling of details and response times under various test conditions like grammar, historical facts, and compliance with instructions.
GPT-4o has shown impressive speeds in generating responses, making it a potentially more effective tool for real-time applications.
However, GPT-4 Turbo maintains a robust performance, particularly in handling complex processing tasks. Both models offer significant improvements over their predecessors, lowering both latency and cost, which is a huge win for developers and end-users alike.
This advancement in AI from OpenAI not only enhances user experience but also expands the possibilities for implementing AI in various sectors. If speed is your top priority, GPT-4o might be your go-to, but for tasks requiring meticulous detail-handling, GPT-4 Turbo holds its ground firmly.
What should I test next? Let me know in the comments.